NCBI使用指南
NCBI使用指南
什么是NCBI?
美国国家生物技术信息中心 ( National Center for Biotechnology Information,NCBI )
National Center for Biotechnology Information (nih.gov)
https://www.ncbi.nlm.nih.gov/从网址上可以看出来它属于
美国国立卫生研究院National Institutes of health(NIH)下属的美国国家医学图书馆National Library of Medicine(nlm)。NCBI设置有与生物技术和生物医学相关的一系列数据库,是生物信息学工具和服务的重要资源。 主要数据库包括DNA序列GenBank (nih.gov),和生物医学文献书目数据库PubMed (nih.gov)。 其他数据库包括NCBI表观基因组数据库。 所有这些数据库都可以通过Entrez搜索引擎在线获取。
NCBI怎么用呢?
要了解怎么用首先要看下NCBI的主页
NCBI主页能多年不变,证明了其首页功能的合理性。
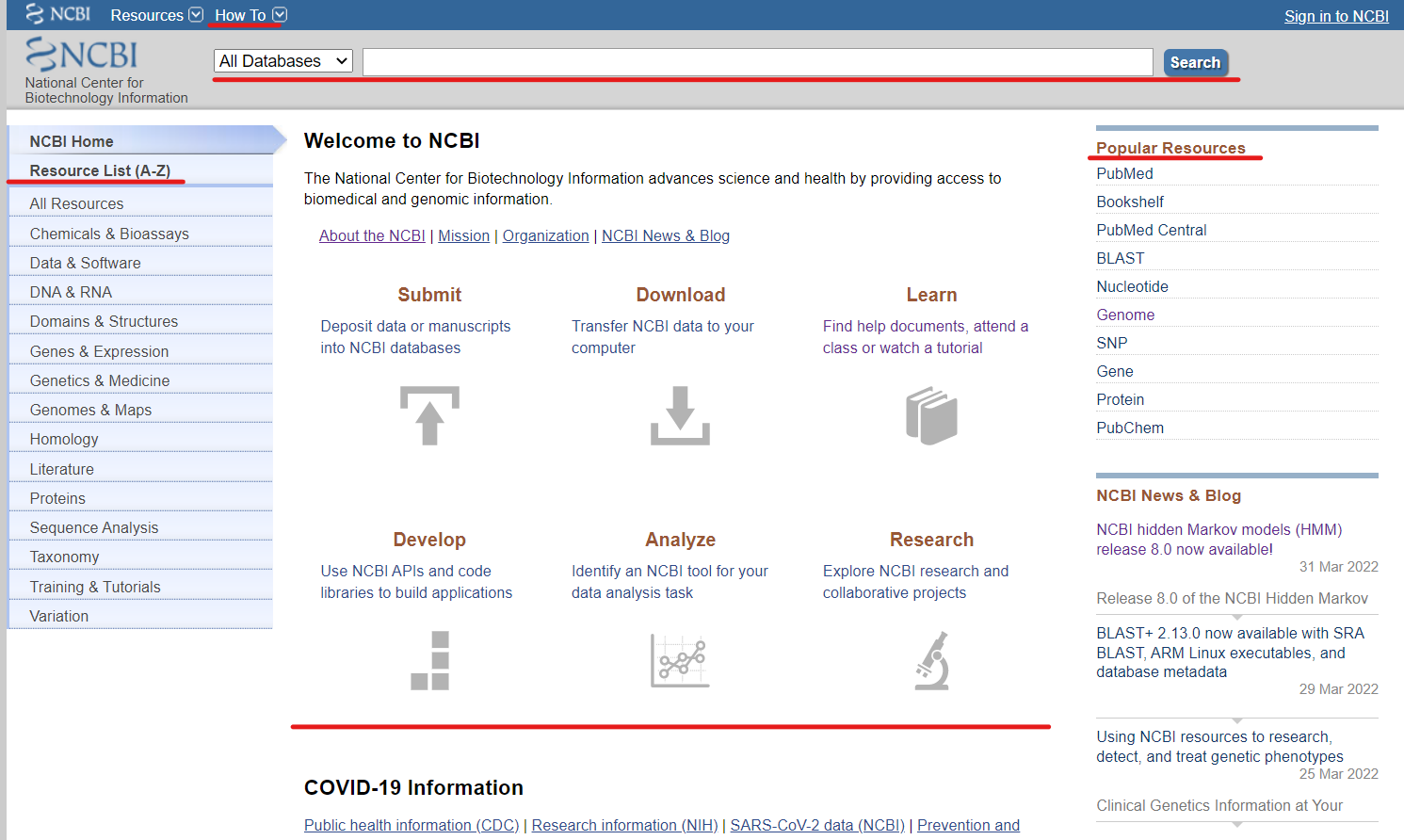
NCBI主页主要常用的就是红线画的板块
- How To|如果你有任何不会用的都可以去这里搜索教程。
- 搜索栏|你能搜索NCBI中的各种数据库
- 中间部分|提交、下载、学习、开发、分析、研究数据
- 左边快捷栏|你能看到NCBI所有资源目录
- 右边热门资源|你能快速使用NCBI的热门资源
常用数据库
当你只有一段DNA、RNA、蛋白序列的时候,你想知道它是什么,这时候BLAST: Basic Local Alignment Search Tool (nih.gov)就是一个很好的工具
BLAST(Basic Local Alignment Search Tool)能够快速比较核酸或蛋白质之间的相似性
帮助你快速找到相似的基因或者蛋白。
对于单核苷酸多态性(SNP)Home - SNP - NCBI (nih.gov)你能快速搜索到SNP位点
GenBank是NIH基因序列数据库,是所有公开可用的DNA序列的注释集合
GenBank是国际核苷酸序列数据库协作的一部分,该协作包括
DNA DataBank of Japan(DDBJ),European Nucleotide Archive(ENA)和NCBI的GenBank。这三个组织每天交换数据。你能够在GenBank上上传和下载各种基因序列
Assembly提供有关组装基因组结构、组装名称和其他元数据、统计报告以及基因组序列数据链接的信息。你能得到各种物种的参考基因组。
RefSeq提供了一组全面、集成、非冗余、注释良好的序列,包括基因组DNA、转录本和蛋白质。RefSeq 序列构成了医学、功能和多样性研究的基础。它们为基因组注释、基因鉴定和表征、突变和多态性分析、表达研究和比较分析提供了稳定的参考。
Conserved Domains)保守域数据库是用于注释蛋白质中功能单元的资源。其域模型集合包括由NCBI构建的一组,该数据库利用3D结构来提供对序列/结构/功能关系的解释。
Structure三维结构提供了有关大分子的生物学功能和进化历史的丰富信息。它们可用于检查序列-结构-函数关系、相互作用、活动位点等。
Gene整合了来自各种物种的信息。记录可能包括命名法、参考序列 (RefSeqs)、图谱、通路、变异、表型以及与全球基因组、表型和位点特异性资源的链接。
GEO(Gene Expression Omnibus)GEO 是一个公共功能基因组学数据存储库,接受基于数组和序列的数据。提供的工具可帮助用户查询和下载实验和精选的基因表达谱。
Protein蛋白质数据库是来自多个来源的序列的集合,包括来自GenBank,RefSeq和TPA中注释编码区域的翻译,以及来自SwissProt,PIR,PRF和PDB的记录。蛋白质序列是生物结构和功能的基本决定因素。
ClinVar一个可搜索的基因数据库,专注于已经完全测序的基因组,并且有一个活跃的研究社区来贡献基因特异性数据。信息包括命名法、染色体定位、基因产物及其属性(例如,蛋白质相互作用)、相关标记、表型、相互作用以及与引文、序列、变异细节、图谱、表达报告、同源物、蛋白质结构域内容和外部数据库的链接。
ClinVar汇总了来自
SNOMED CT,GeneReviews,Genetic Home Reference,Office of Rare Diseases,MeSH和OMIM®等来源的具有遗传基础的医疗条件的名称。ClinVar还汇总了来自
Human Phenotype Ontology(HPO),OMIM和其他来源的相关特征的描述。跟踪每个信息源,并可用于查询。
PubChemPubChem主要含有小分子,但也含有较大的分子,如核苷酸,碳水化合物,脂质,肽和化学修饰的大分子。我们收集有关化学结构、标识符、化学和物理特性、生物活性、专利、健康、安全、毒性数据等信息。
dbVardbVar是NCBI的人类基因组结构变异数据库 — 大于50 bp的大变体,包括插入,删除,重复,反转,移动元素,易位和复杂变异
PubMed类似于Web of science,不过专注于医学和生命科学帮助快速检索书籍和文献。
一条常见的查询流程
获取数据
检索数据
针对需求具体查询
有一段序列使用BLAST找到近缘基因
从Pubmed上的文章得到基因名或者PMID
通过检索疾病功能来搜索基因
- 检索基因
- 在Gene数据库中搜索基因
以TP53为例:

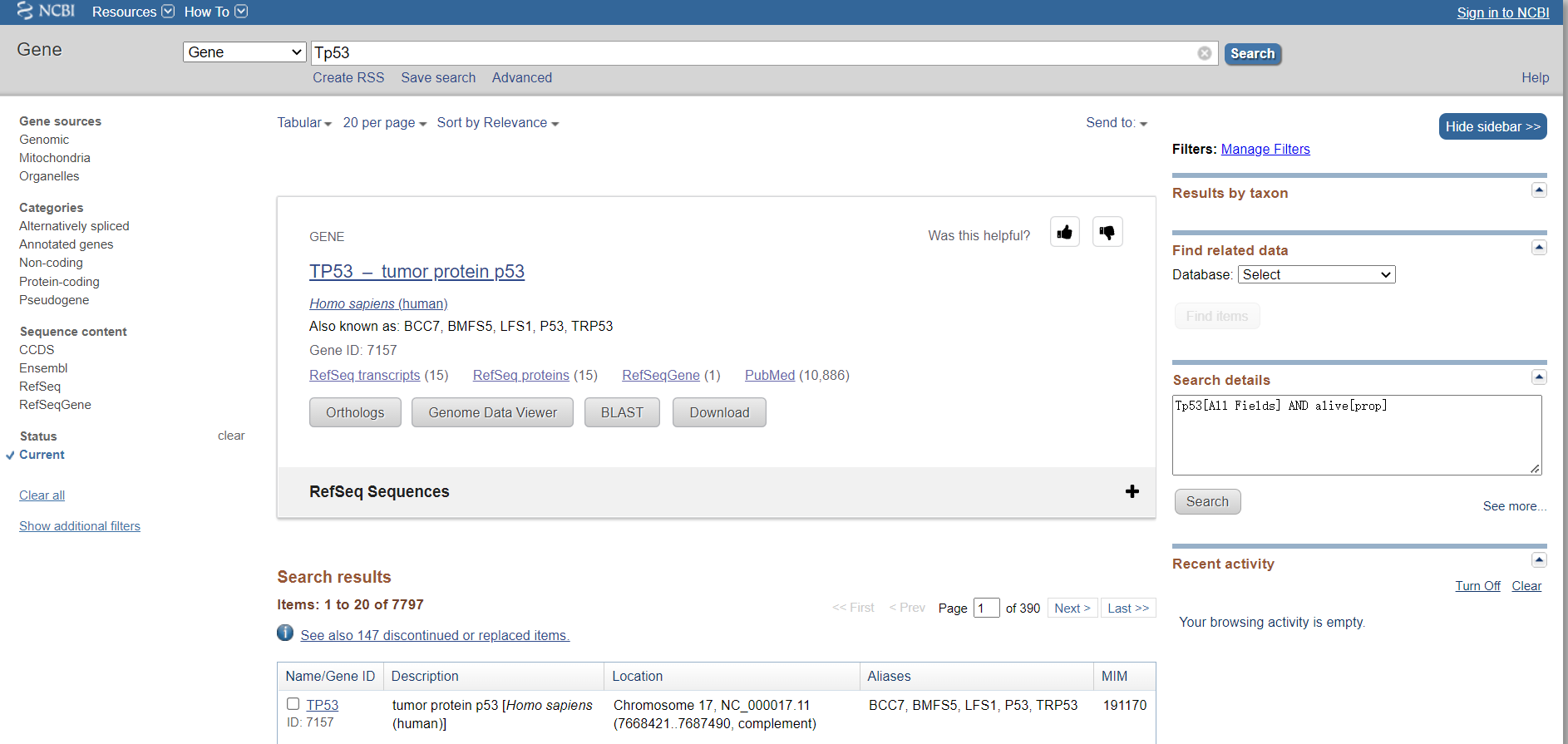
- 针对针对需求具体查询
以TP53为例:
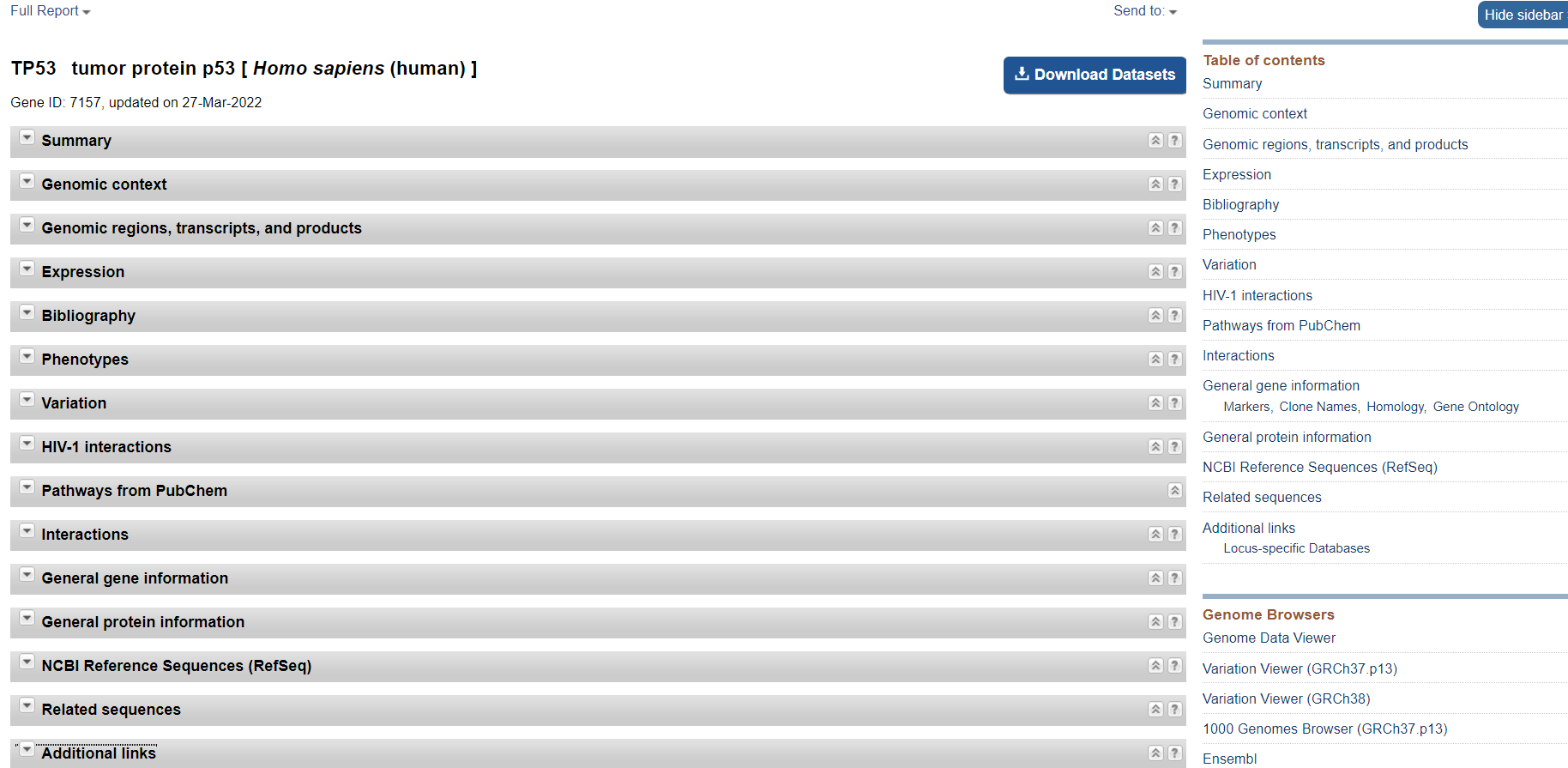
- Summary

对TP53的总结
包括基因名称、来源、类型、别称、是否证实、总结、同源等
- Genomic context
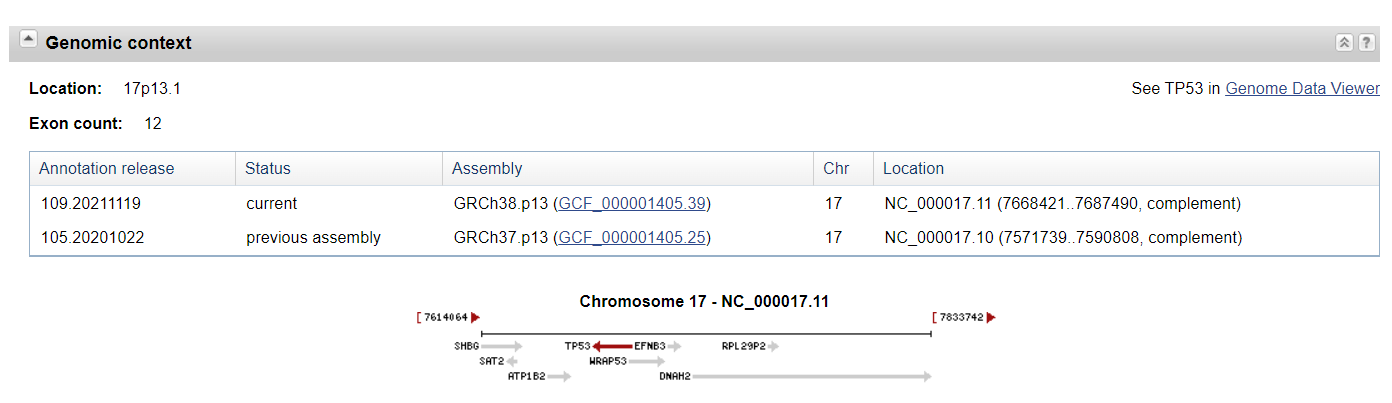
这个部分我们可以查看这个基因在DNA水平染色体位置上的相关信息。同时也可以简单了解起上下游的基因。如果想要看详细信息,我们可以通过 Genome Data View来查看结果。
- Genomic regions, transcripts, and products
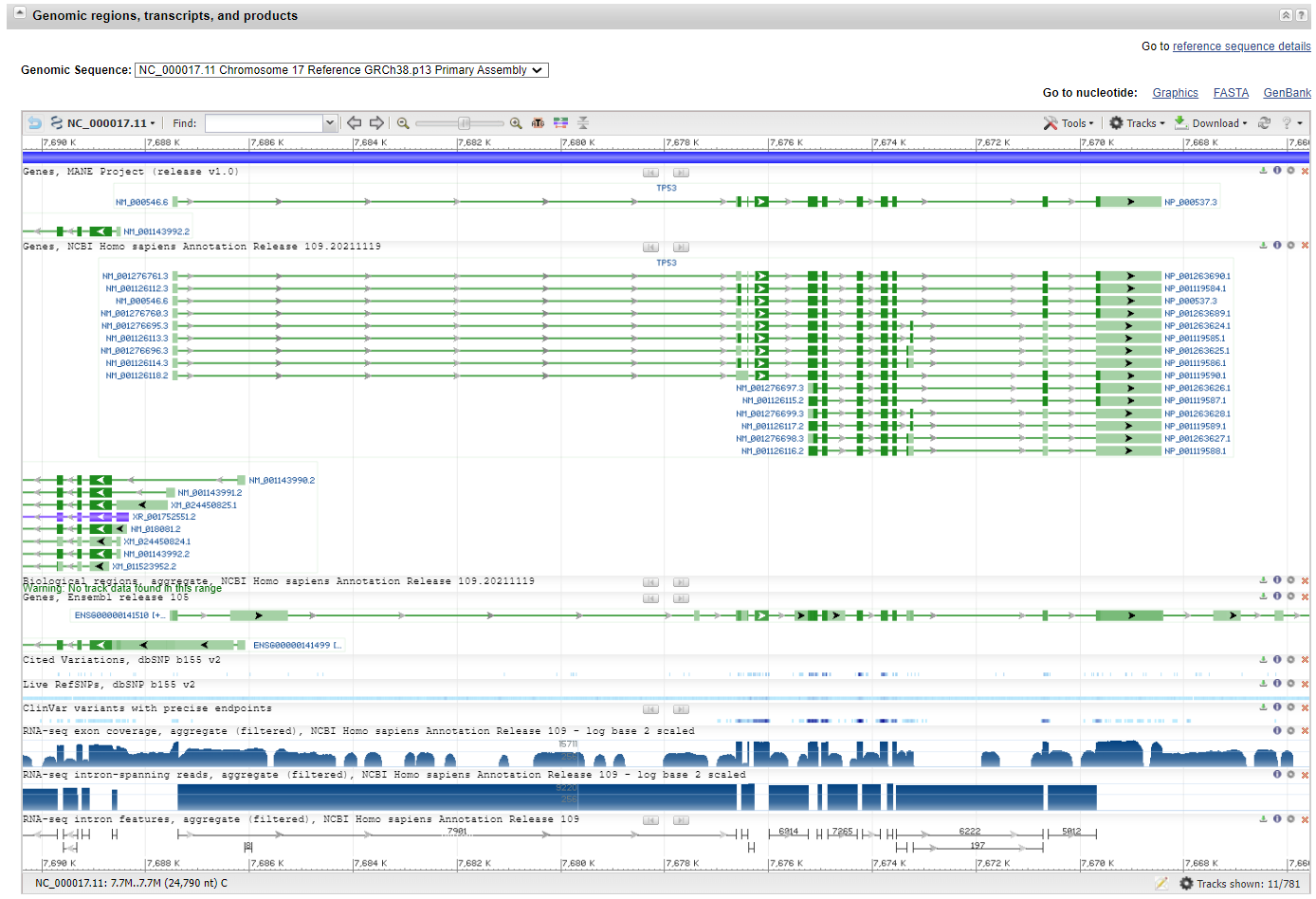
这个部分我们可以在RNA水平上各个转录本的相关信息
- Expression
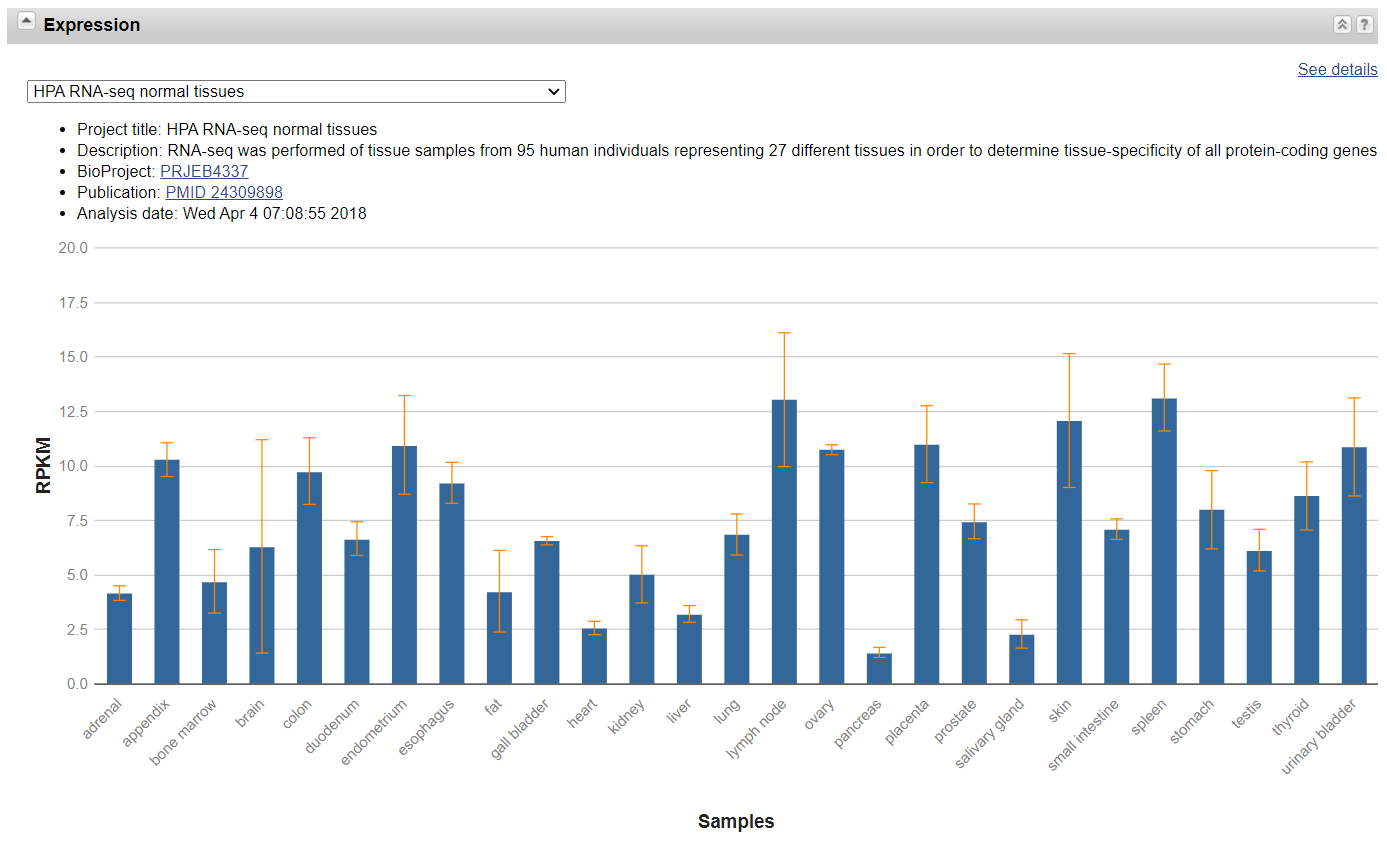
可以查看在二代测序的数据当中,不同的正常组织中 TP53的基因表达情况
- Bibliography
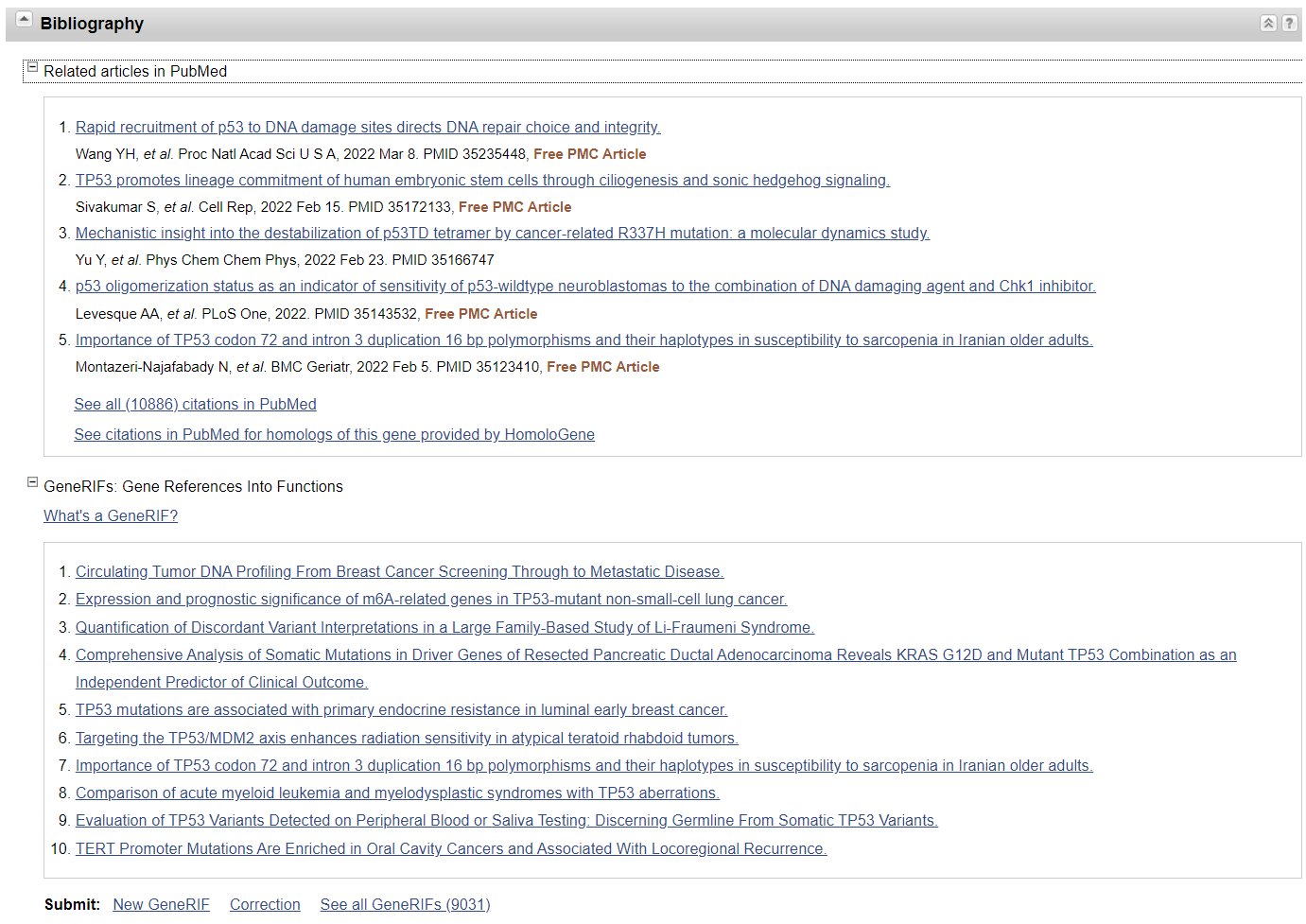
在这个部分,我们可以查看和这个基因相关的所有相关文献。这个部分主要分为两个部分
- 所有和 TP53相关的所有文献
GeneRIFs(Gene References Into Functions),这个功能类似于筛选出和这个基因功能有关的文献
- Phenotypes
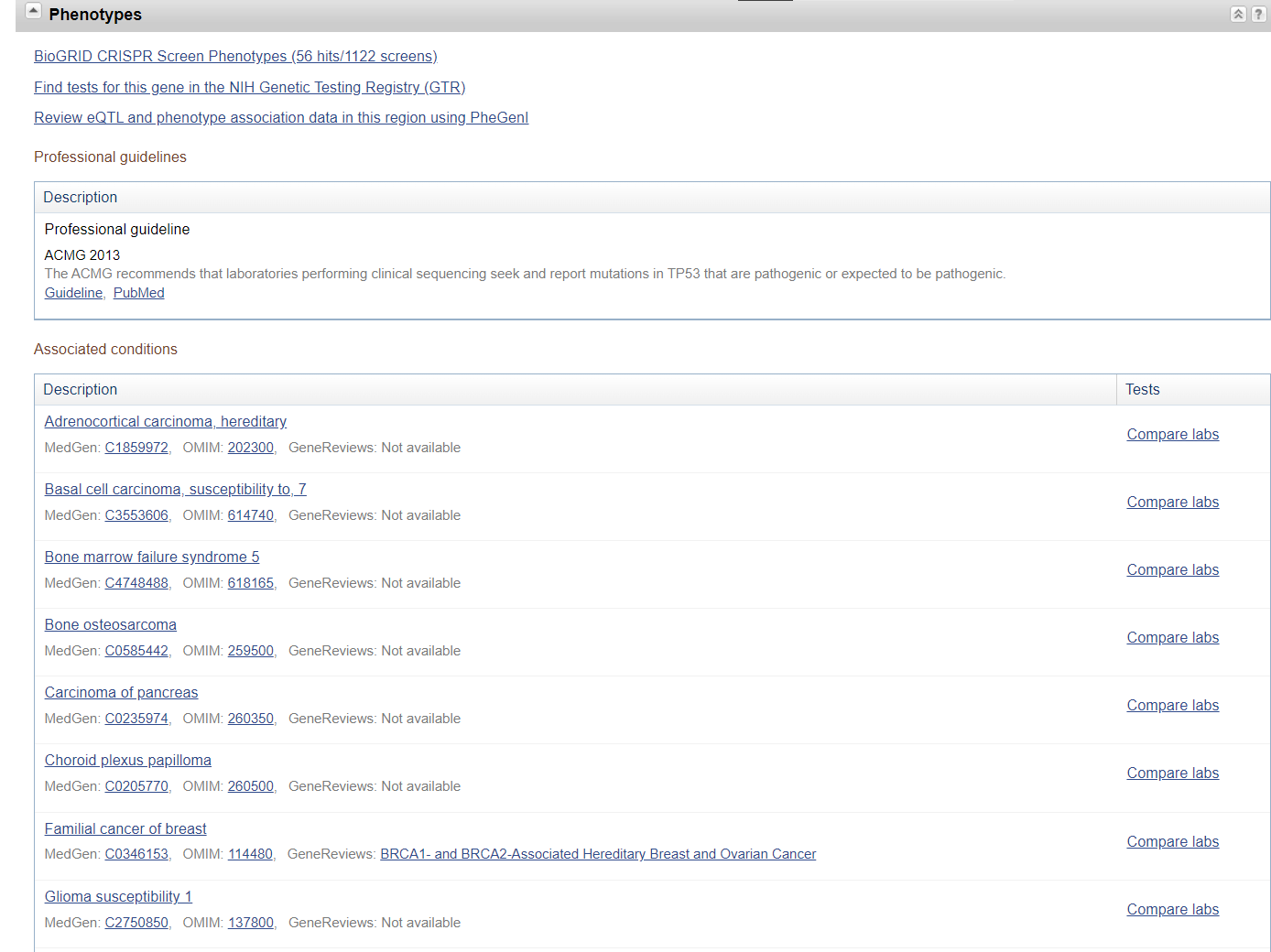
这个部分可以用来查找和 TP53相关的表型情况。包括:相关的疾病信息;拷贝数变异以及 GWAS情况
- Pathways from PubChem
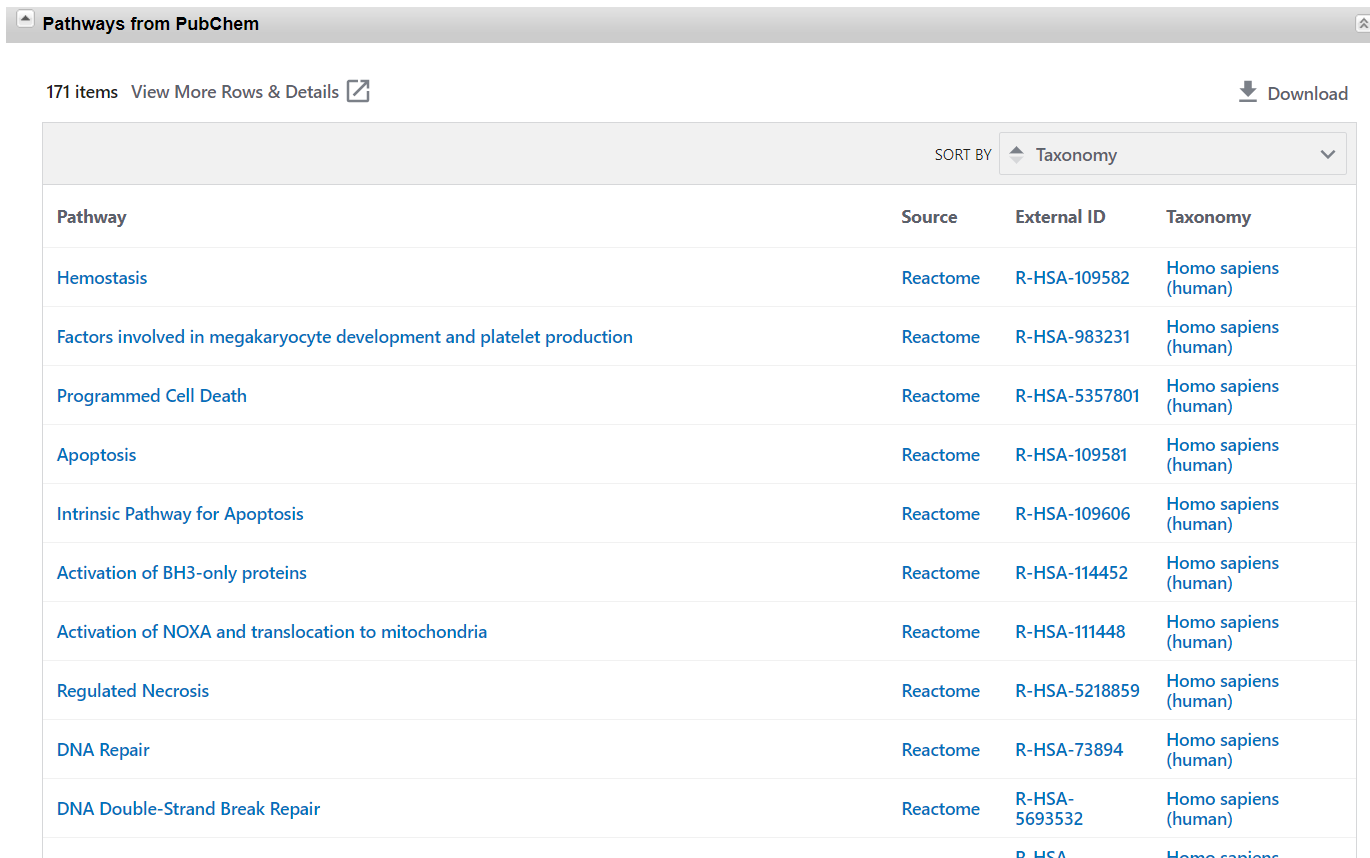
这个部分我们可以了解和 TP53有关的通路。其数据结果来自于各个综合性的通路分析数据库。
- Interactions
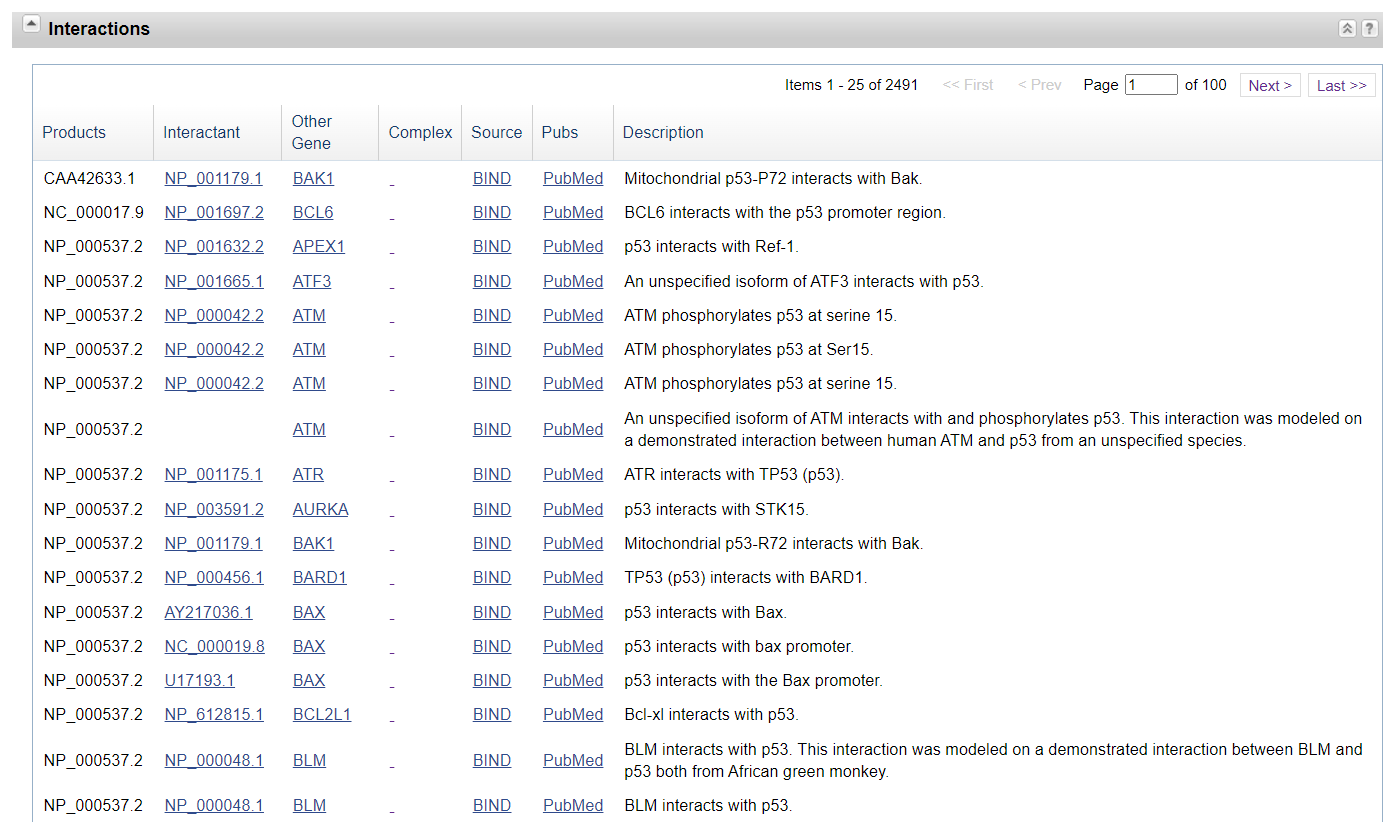
这个部分我们可以了解和 TP53的互作情况。
- General gene information&General protein information

这个部分我们可以了解和 TP53的markers、同源性、克隆体、基因本体(GO)、以及对应的蛋白。
同源基因可以在Homology里查询
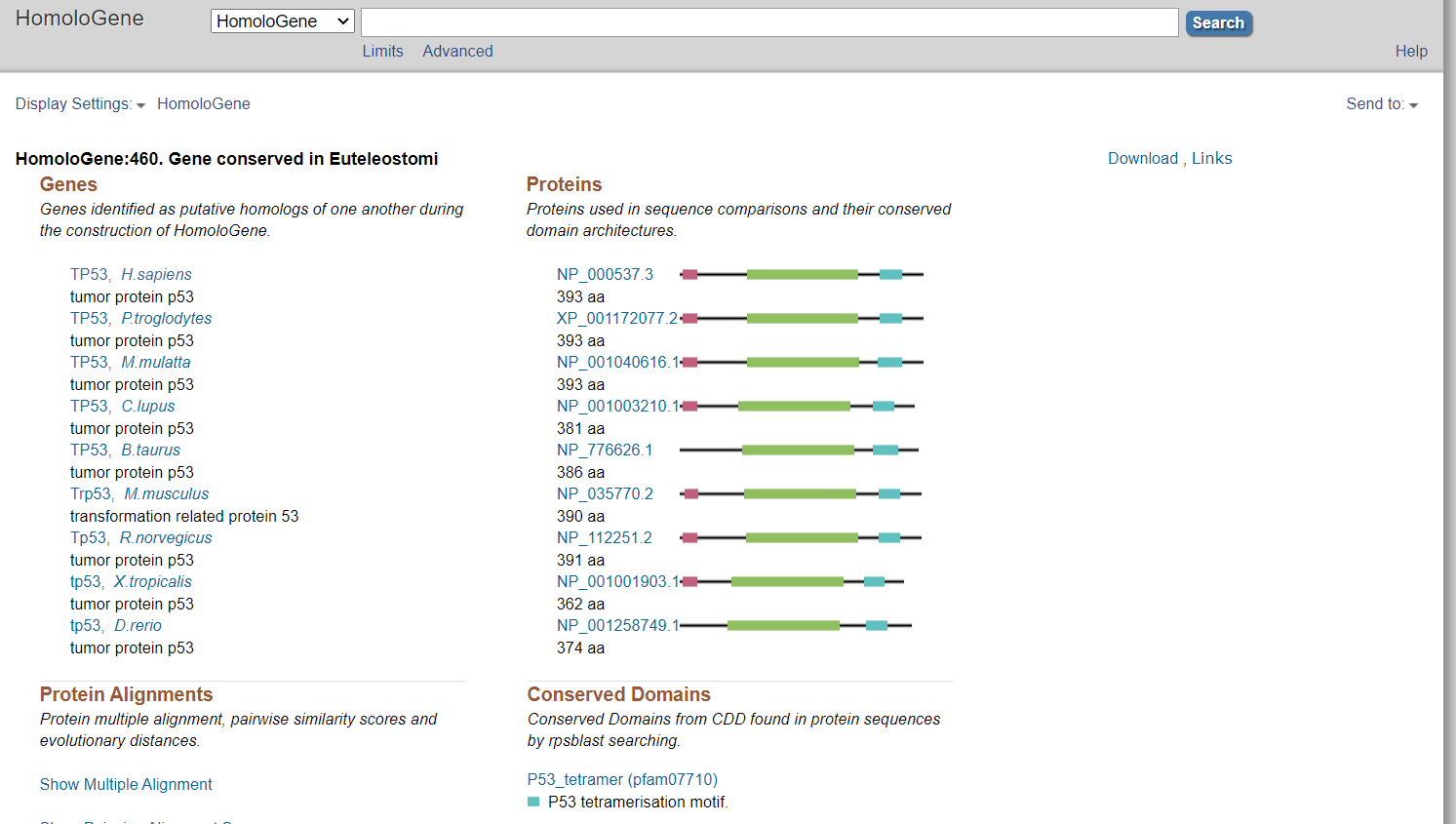
- NCBI Reference Sequences (RefSeq)

这个部分,可以查看 TP53的所有基因序列信息。我们可以查看其基因组的序列,也可以查看每个转录本的序列以及转录本翻译成蛋白的序列。其中关于转录本的信息也有简单的介绍。如果需要详细的介绍点击链接即可。
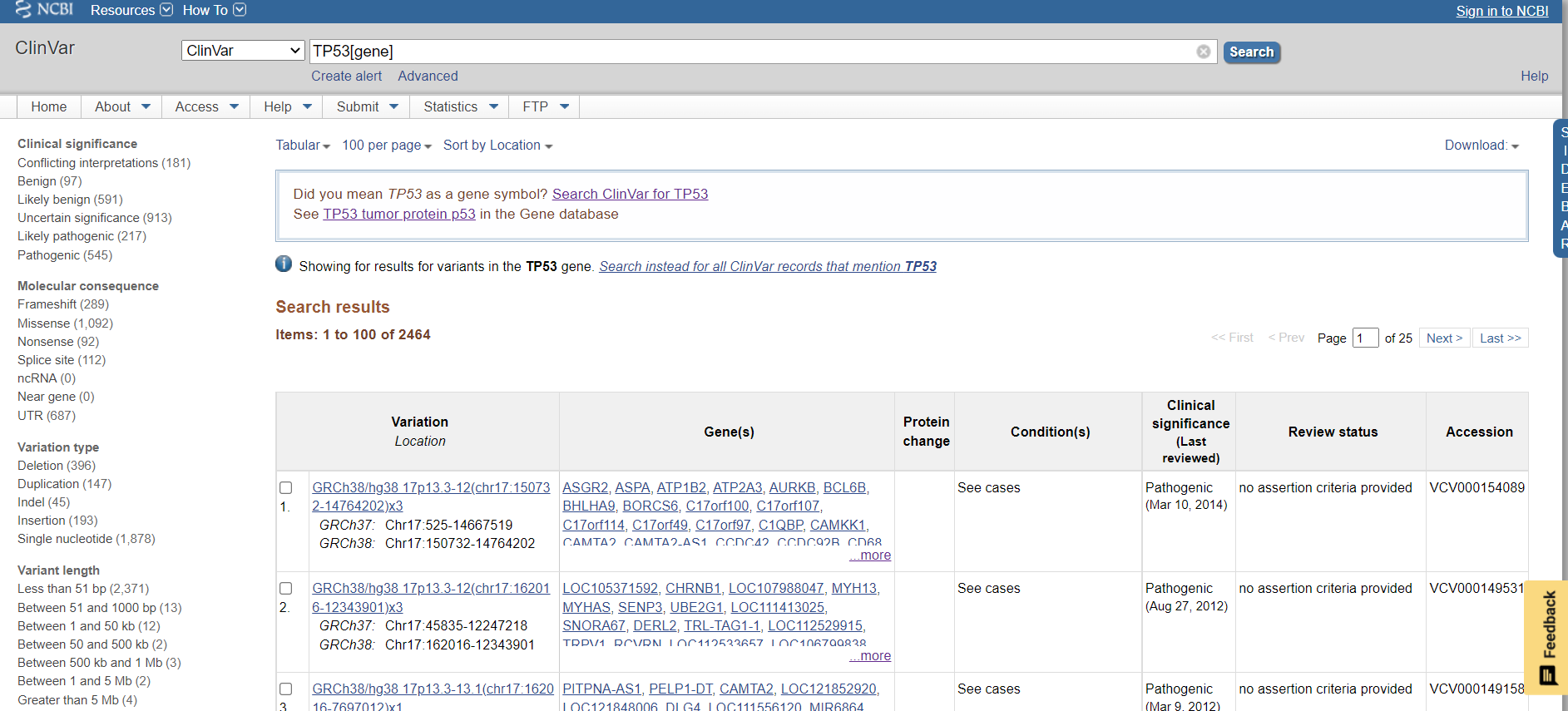
- [NEW]Variation

这个部分,可以查看 TP53的在ClinVar和dbVar相关变体和SNP位点
ClinVar中的变体
dbVar中的变体
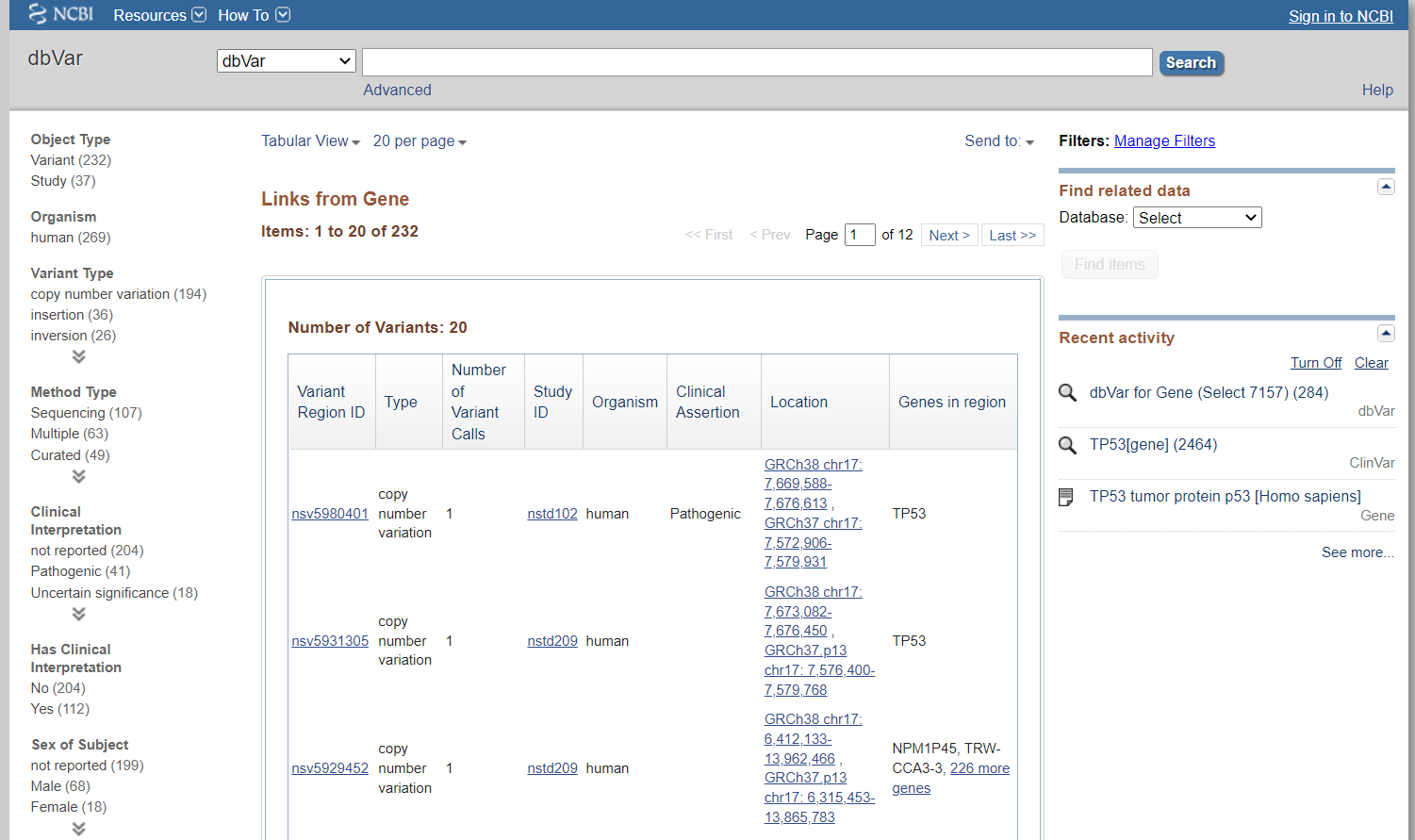
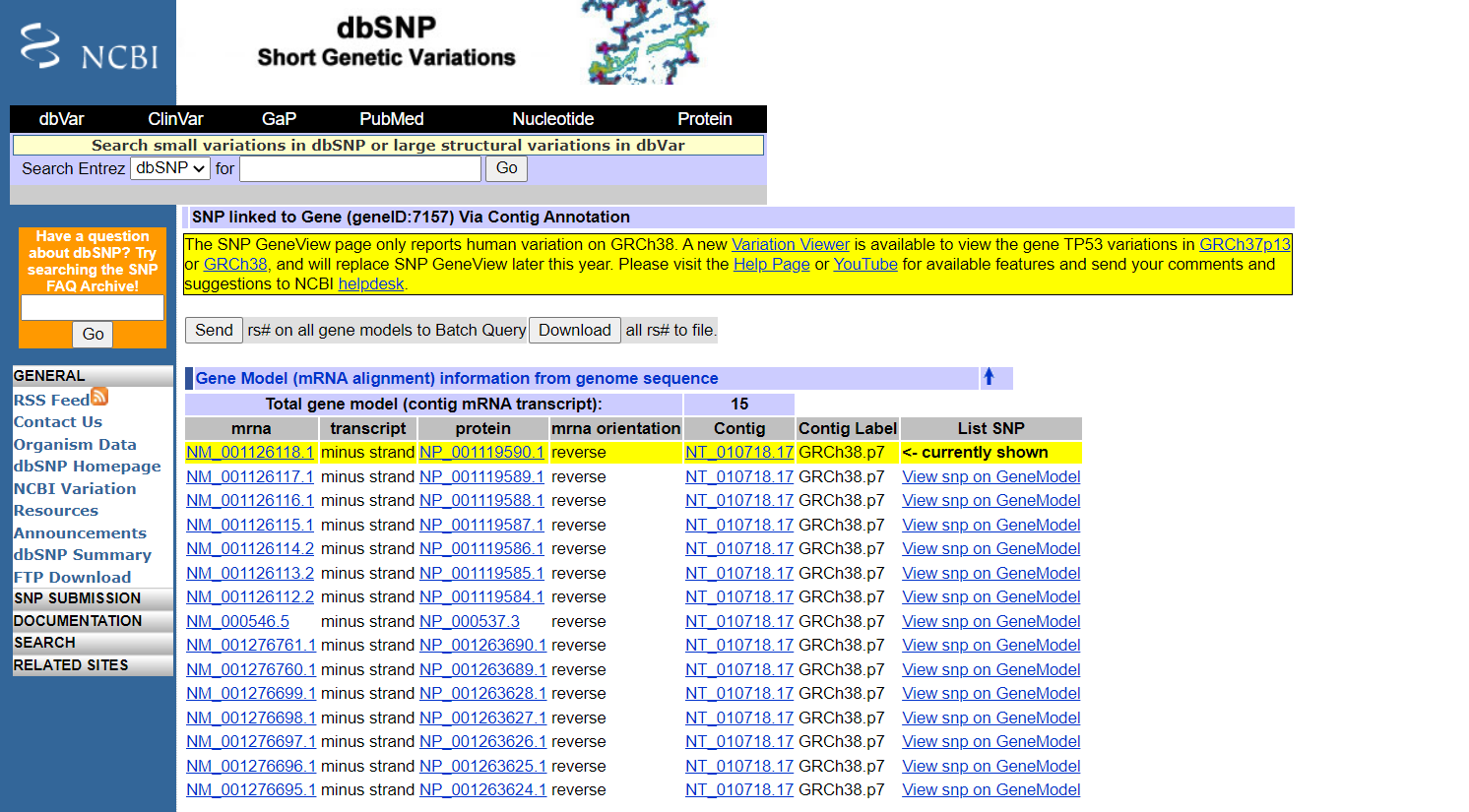
dbSNP中的SNP
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!